מטרה: ללמוד איך להשתמש במודל K שכנים הכי קרובים למטרת פרדיקציה
זמן הקריאה: כ-10 דקות
בהדרכה זו נדגים:
- עקרונות שימוש במודל K-שכנים הכי קרובים
מבוא: קיים מספר רב של מודלי ניבוי. לכל מודל יש יתרונות וחסרונות. מודל KNN הוא די פשוט להבנה. כדי לעשות חיזוי משתמשים בתצפיות הכי קרובות לתצפית שעבורה בונים חיזוי. במודל יש לבחור בכמה שכנים להשתמש ומהי מטריקת המרחק. אפשר להשתמש במודל זה גם עבור בעיות סיווג וגם עבור בעיות רגרסיה.
שימוש ב-KNN עבור בעיות רגרסיה:
נשתמש בנתונים של HOUSING. משתנה מטרה כאן היא MEDV – מחיר של בית
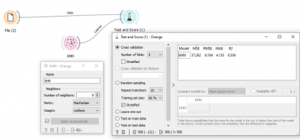
כאן השתמשנו ב-9 שכנים ומטריקת MANHATTAN. כמו שאפשר לראות איכות של מודל לפי R בריבוע היא 0.559.
ניתן לנסות לשפר את המודל. נבחר 3 שכנים ומטריקת MAHALOBIS, איכות המודל עלתה ל0.79.
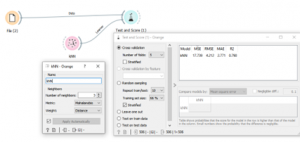
שימוש בKNN עבור בעיות רגרסיה. נבחר נתונים של מחלות לב: HEAR DECEASE.

עבור 3 שכנים ומטריקת EUCLIDEAN איכות של מודל לפי קריטריון AUC הינה 0.628.
ניתן לנסות לשפר איכות המודל על ידי שינוי מספר שכנים ומטריקת מרחק.

.