למד מה זה מדעי הנתונים והחשיבות שלו.
למד את השלבים של פרויקט במדעי נתונים וכיצד ליישם אותם בPython וחבילת sklearn.
למד כיצד להעריך ולמדוד את ביצועי המודל שלך באמצעות חבילת sklearn.
Here you can find the explanations – how to use a confusion matrix for regression problems. The confusion matrix is a useful tool for classification problems sometimes we can use it also for regression problems.
א) איך לפתור בעיות רגרסיה – חיזוי מחיר של בית עבור אוסף נתונים HOUSING
ב) נעריך איכות של מודל בעזרת שימוש במודול matrix confusion
:מבוא
בבעיות רגרסיה משתנה מטרה מקבל ערכים מספריים, למשל מחיר של בית. אפשר להעריך איכות של מודל רגרסיה בעזרת מקדם R בריבוע או בדרכים אחרות. מטריצת בלבולים עוזרת להבין מהו איכות של מודל סיווג. האם אפשר להשתמש במטריצת בלבולים עבור בעיות רגרסיה? כן, לאחר הכנה מתאימה.
1) יש לפתוח נתונים HOUSING בעזרת מודול FILE. בנתונים האלו המטרה היא לתת תחזית עבור משתנה מטרה כמותי MEDV

2) בעזרת מודולים REGRESSION LINEAR ו -SCORE AND TEST נבנה מודל חיזוי עבור הנתונים:
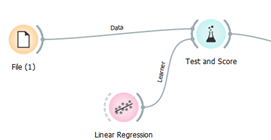
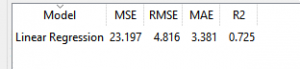
אפשר להעריך איכות המוד ל בעזרת מקדם R בריבוע
3) כדאי להשתמש במטריצת בלבולים נצטרך להפוך נתונים שלנו לאיכותיים, נעשה זה בעזרת מודול .FEATURE CONSTRUCTOR
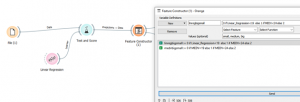
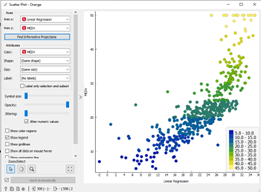
כמו שאפשר לראות אנו חלקנו תחום של מחירים ל3- אזורים,:small big ,medium ועכשיו נוכל מטריצת בלבולים בעזרת מודול PIVOT
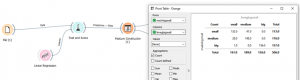
אם נסתכל במטריצה אפשר לראות שעל בתים יקרים המודל שלנו טעה רק פעם אחת ועבור ביתים זולים מודל שלנו ברבע מהמקרים נותן תחזית שגויה.
אפשר גם להשתמש במודול PLOT SCATTER . אבל לפעמים הצגה בעזרת מטריצת בלבולים יותר פשוטה
איגוד מדעי הנתונים בלשכת המהנדסים
https://www.aeai.org.il/professional-society/data-science/
פודקאסטים בנושא מדע הנתונים:
https://www.aeai.org.il/talking-data-podcast/
פרק 9 – מהפכת Moneyball
פרק 8 – הטיות מגדריות במחקר כמותי
פרק 7 – סביבת העבודה של מדען הנתונים
פרק 6 – מבוא למערכות המלצה
פרק 5 – מדעי הנתונים להגנת הסביבה
פרק 4 – מבוא לעיבוד שפה טבעית (NLP(
פרק 3 – רשתות למידה
פרק 2 – שוק העבודה למדעני נתונים
פרק 1 – אמנות חקר הנתונים
למד שיטה של למידת המכונה – Support Vector Machine (SVM), וכיצד להשתמש בה עם חבילת sklearn.
דוגמה של מקרה שימוש לניתוח סנטימנטים עם בסיס נתונים של Kaggle.
דוגמה של מקרה שימוש לבעיית סיווג נושאים עם בסיס נתונים של Kaggle.
Decision tree is a helpful tool both for classification and regression tasks.
שימוש במודל עץ החלטה עבור בעיות סיווג
מטרה: בשיעור זה נדגים ונסביר עקרונות שימוש למודל יחסית פשוט ומאוד שימושי עץ החלטה. נדגים שימוש במודל על בעיות סיווג.
זמן קריאה: 15 דקות
מטלה לביצוע: מובנת בתוך המסמך

Look-alike photos\images
Orange widget – Neighbors accept an image and output the nearest neighbors of that image.
https://orangedatamining.com/blog/2020/2020-01-08-neighbors-images/
חיפוש תמונות דומות בעזרת מודול לחיפוש שכנים
מטרה: בשיעור זה נלמד איך לחפש תמונות דומות לתמונה נתונה בעזרת מודול חיפוש שכנים. הכלי יכול לעזוק לחוקרים שעובדים עם תמונות.
זמן קריאה: 10 דקות
מטלה לביצוע: מובנת בתוך המסמך

Simple linear regression in Orange
Linear regression is a very simply technique. It can be usefor for a large number of prediction tasks. In this tutorial, you will build linear regression model step-by-step in Orange.
The tutorial does not assume any prior background in statistics or programming.
Linear regression: wine price prediction (55 min)
חיזוי מחיר עתידי של יין בעזר בעזרת רגרסיה ליניארית
פתרון בעיות רגרסיה בעזרת רגרסיה ליניארית בתוכנת Orange
מטרה: ללמוד מודל פשוט ושימושי רגרסיה ליניארית עבור בעיות שבהם משתנה תלוי הוא מספרי.
זמן קריה: 30-20 דקות
מטלה לביצוע: מובנת בתוך המסמך

Build your deep network freely in 10 minutes
LOBE is a free software that has almost everything you need to bring your machine learning project to life. In the tutorial, we demonstrate how to build a network for image classifications.
Video build network in 10 minutes
בניית רשת נוירונים לקבצי תמונות ב-10 דקות
מטרה:
- להכיר מערכת חינמית LOBE.AI לבנית רשת נוירונים לעבודה עם תמונות
- ללמוד איך לאסוף תמונות ממצלמת מחשב תוך דקות ספורות
- ללמוד איך לאמן רשת נוירונים כדי לפתור בעיית סיווג תמונות
זמן קריאה: 10 דקות
מטלה לביצוע: כ-10 דקות לביצוע
KNN is a very popular and simple prediction tool.
Below we will demonstrate how to use random forest in Orange Data Mining both for regression and classification problems.
מטרה: ללמוד איך להשתמש במודל K שכנים הכי קרובים למטרת פרדיקציה
זמן הקריאה: כ-10 דקות
בהדרכה זו נדגים:
- עקרונות שימוש במודל K-שכנים הכי קרובים
מבוא: קיים מספר רב של מודלי ניבוי. לכל מודל יש יתרונות וחסרונות. מודל KNN הוא די פשוט להבנה. כדי לעשות חיזוי משתמשים בתצפיות הכי קרובות לתצפית שעבורה בונים חיזוי. במודל יש לבחור בכמה שכנים להשתמש ומהי מטריקת המרחק. אפשר להשתמש במודל זה גם עבור בעיות סיווג וגם עבור בעיות רגרסיה.
שימוש ב-KNN עבור בעיות רגרסיה:
נשתמש בנתונים של HOUSING. משתנה מטרה כאן היא MEDV – מחיר של בית
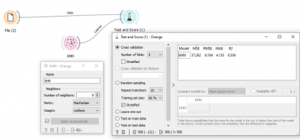
כאן השתמשנו ב-9 שכנים ומטריקת MANHATTAN. כמו שאפשר לראות איכות של מודל לפי R בריבוע היא 0.559.
ניתן לנסות לשפר את המודל. נבחר 3 שכנים ומטריקת MAHALOBIS, איכות המודל עלתה ל0.79.
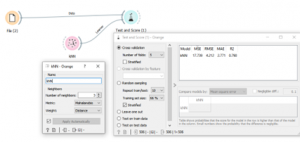
שימוש בKNN עבור בעיות רגרסיה. נבחר נתונים של מחלות לב: HEAR DECEASE.

עבור 3 שכנים ומטריקת EUCLIDEAN איכות של מודל לפי קריטריון AUC הינה 0.628.
ניתן לנסות לשפר איכות המודל על ידי שינוי מספר שכנים ומטריקת מרחק.

.
Random forest is a very robust and powerful prediction tool.
Below we will demonstrate how to use random forest in Orange Data Mining both for regression and classification problems.
המטרה : ללמוד אלגוריתם גמיש לחיזוי – יער אקראי
זמן הקריאה: כ-20 דקות
בהדרכה זו נדגים:
- איך להשתמש במודול RANDOM FOREST ולבנות מודלים לניבוי
מבוא: קיים מספר רב של מודלי ניבוי. לכל מודל יש יתרונות וחסרונות. מודל של יער אקראי הוא אחד המודלים הגמישים אם יכולת אינטרפרטציה נמוכה. בדרך כלל נשתמש במודל זה אם איכות ניבוי יותר חשובה מיכולת לפרש את התוצאות.
רעיון של המודל: לגדל בצורה חכמה מספר עצי החלטה (מודלים יותר פשוטים) ואז להשתמש בהרבה עצים כדי לקבל החלטה סופית.
שימוש ביער אקראי עבור בעיות רגרסיה:
- פתחו את נתונים HOUSING בעזרת מודול FILE ובנו מודל לחיזוי מחיר עתידי של בית בעזרת מודול RANDOM FOREST, בעזרת מודול TEST AND SCORE העריכו איכות של המודל

אפשר לנסות לבנות מודלים אחראים ולהשוות בין תוצאתם:
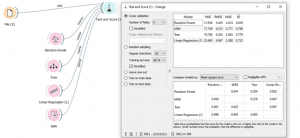
כמו שאפשר לראות, כאן התקבלו תוצאות הכי טובות עבור מודל יער אקראי.
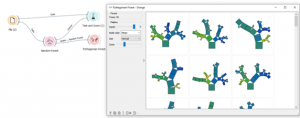
אפשר לנסות לעשות ויזואליזציה של יער בעזרת מודול PYPHOGORIAN FOREST
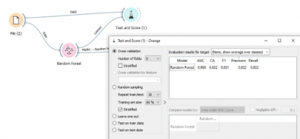
שימוש ביער אקראי עבור בעיות סיווג דומה מאוד לשימוש עבור בעיות רגרסיה.
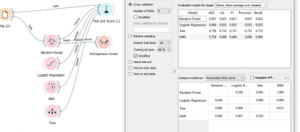
כעת בחרו בנתוני של מחלות לב – heart disease
גם כאן אפשר להשוואת ביצועים של מודלים שונים
אפשר להיעזר בPYTHOGORIAN FOREST כדי לראות את היער שהתקבל
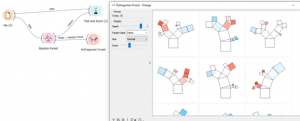
In this document we will demonstrate how to do topic modeling by LDA in Orange Data Mining. This document can be usefull for text data analysis.
מטרה: ללמוד איך למצוא נושאים בנתונים טקסטואליים בעזרת LDA
זמן הקריאה: כ-15 דקות
בהדרכה זו נדגים:
- איך לעבוד עם נתונים טקסטואליים
- איך למצוא נושאים אבסטרקטים בקורפוס
מבוא: חיפוש נושאים אבסטרקטים בקורפוס מבוס על חיפוש אשכולות של מילים עבור כל מסמך. בדרך כלל בכל מסמך אפשר למצוא נושאים שונים במשקל (חשיבות) שונה.
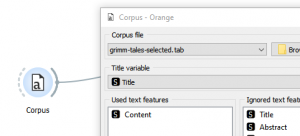
- פתחו אגדות של אחי גרים בעזרת מודול CORPUS
- בצעו עיבוד מקדים של הנתונים – בסטנדרטי בעזרת מודול PREPROCESS TEXT
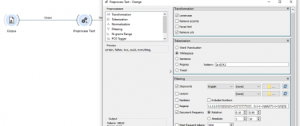
בשלב זה נהפוך כל האותיות לאותיות קטנות, ונשארי רק את המילים עם תדירויות בין 0.1 ל0.9
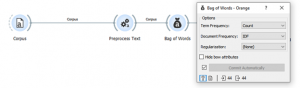
- נהפוך כל טקסט לשק של מילים, כדאי להשתמש קריטריון IDF היות ובדרך כלל הוא עובד די טוב עבור חיפוש נושאים.
- בעזרת מודול TOPIC MODELING נמצא 6 נושאים בקורפוס שלנו.
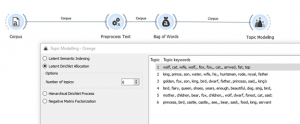
כמו שאפשר לראות נושא ראשון מדבר כנראה על חיות. נושא שני כנראה מדובר על אגדות קסם היות ויש מילים כמו: king, prince, wife, etc
אפשר להשתמש במודול LDAVIS כדי לנסות להבין את התוצאות בצורה יותר מעמיקה
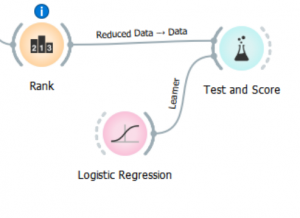
Ranking of attributes can help both in regression and classification problems.
The rank model scores independent variables according to their importance.
בחירת המאפיינים הכי חשובים
מטרה: ללמוד איך אפשר לבחור מאוסף משתנים בלתי תלויים המשתנים החשובים לניבוי,כלומר ללמוד איך ניתן לצמצם את מספר משתנים בלי לפגוע באיכות המודל.
זמן קריאה: 15 דקות
מטלה לביצוע: מובנת בתוך המסמך

There’s nothing more beautiful than seeing your data in plot. Violin plots are thus great for exposing underlying distributions, especially if they are multimodal, which cannot be determined from the box plot and histogram.
בניית גרף ויולין בעזרת אורנז’
מטרה: בשיעור זה נלמד כלי עזר נוסף לויזואליזציה – גרף ויאולין. הכלי מאוד פשוט לשימוש ומאפשר הצגה נוחה לתנונים קמותיים.
זמן קריאה: 10 דקות
מטלה לביצוע: מובנת בתוך המסמך
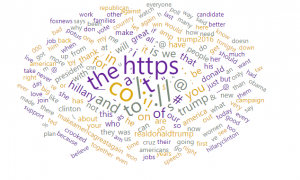
Word cloud is a useful way to visualize text data.
Words are presented in the form of cloud, their size denoting the frequency of the word in the data (corpus)
Word Cloud – example
בניית ענן מילים באורנז
מטרה: לממוד כלי עזר לעבודה עם נתוני טקסט. בעזרת ענן מילים חוקר אוכל לבצע ויזואליזציה וסיכום של נתונים בצורה מונחשית.
זמן קריאה: 10 דקות
מטלה לביצוע: מובנת בתוך המסמך
Standard protocol for data analysis
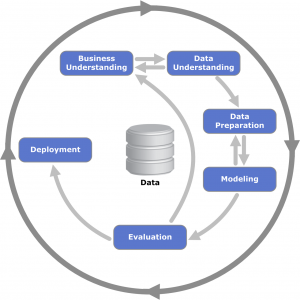
Cross-industry standard process for data mining
The cross-industry standard process for data mining, known as CRISP-DM is an open standard process model that describes common approaches used by data mining experts.
In this section, we describe the main advantages of the protocol, its weak and strong sides.
For an explanation in English press.
CRISP-DM (Hebrew) – 10 minutes
CRISP-DM תהליך סטנדרטי לעבודה עם נתונים
בפרק זה נכיר תהליך סטנטרטי לעבודה עם נתונים
CRISP-DM מאפשר לעבוד עם דאטה בצורה מסודרת ושיטתית.
בוידאו מוסר צריונל של כל אחד מהשלבים ונתונות דוגמאות לשימוש
Spiralogram is a useful visualization tool.
It helps us to understand better the seasonality and pereodicity in time series.
מטרה: ללמוד איך להציג סדרות זמן בצורה ויזואלית נוחה להבנה וניתן בעזרת מודול spiralogram
זמן הקריאה: כ-15 דקות
בהדרכה זו נדגים:
- איך להוריד נתונים מאתר תחרויות של מדעני נתונים KAGGLE
- איך לפתוח את הנתונים בתוכנה חינמית ORANGE
- איך להשתמש במודול spiralogram כדי להציג את הנתונים בצורה ויזואלית
מבוא: סדרות זמן time series הם נתונים הנאספות לאורך הזמן. למשל, טמפרטורה ימית הנמדדת פעם ביום, או מחיר מנייה הנמדד פעם בדקה.
הורדת נתונים: יש להוריד וקובץ בשם ma_lga_12345.csv מאתר תחרויות של מדעני נתונים KAGGLE.
https://www.kaggle.com/datasets/htagholdings/property-sales?resource=download
פתיחת נתונים בעזרת מודול file: הריצו תוכנה ORANGE ואז פתחו את הנתונים בעזרת מודול file
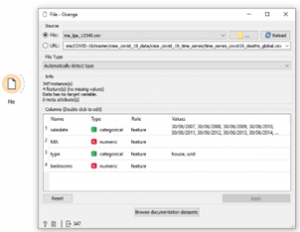
כמו שאפשר לראות מתיור הקצר בנתונים שלנו יש 347 תצפיות ו-4 מאפיינים: MA מחיר, SALEDATE תאריך מכירה, TYPEסוג של הבית, מספר חדרי שיני.
אשפר לחקור את הנתונים בעזרת כלים סטנדרטים לאנליזה ראשונית: data table, feature statistics, distributions
אבל היות ומדובר בסדרת הזמן, נעזר בכלים מתאימים יותר, למשל בספיראלוגרם.
בעזרת מודל EDIT DOMAIN שינו את סוג של משתנה SALEDATE לסוג TIME ואז חברו את התוצאה למודול SPIRALOGRAM כמו בציור למעטה
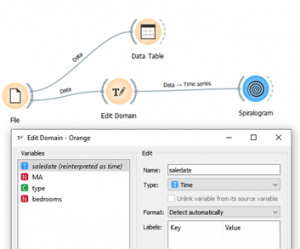
כעת פתחו את המודול ספירלוגרם:
בחרו time period להיות שווה saledate במרווחי זמן – שנה, radial להיות שווה למספר חדרי שינה, כדאי לראות שוני במחרה בתים לפי מספר חדרי שינה ו-сolor להיות שווה למחיר .MA
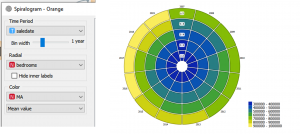
כמו שאפר לראות בקלות – מחירה בית עולים משנה לשנה וככל שיש יותר מספר חדרי שינה מחרי בית גם כן עולים.